نبیل
تکنیکی معاون
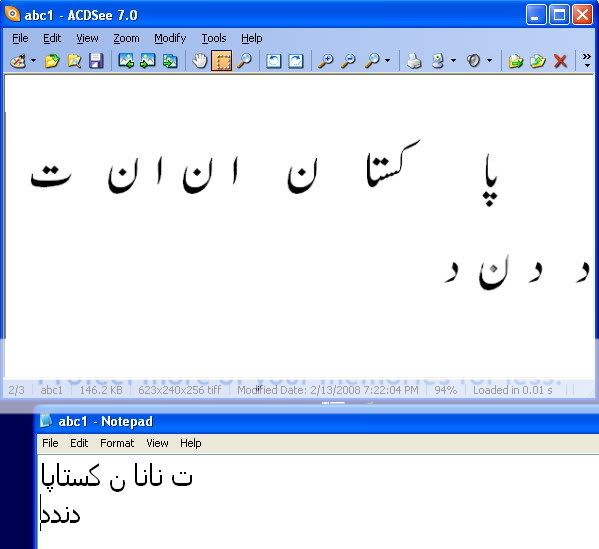
شکریہ جواد۔ اگرچہ یہ کافی بنیادی نوعیت کی بصری شناخت ہے، لیکن یہ بطور ایک پروف آف کانسپٹ کے استعمال کی جا سکتی ہے۔ آپ نے جو تصویری متن استعمال کیا ہے، اس میں ترسیمے واضح طور پر الگ الگ ہیں اور نسبتاً سادہ ہیں۔غالبا اسی وجہ سے ان کی شناخت ممکن ہوئی ہے۔ میں نے کچھ عرصہ قبل امیج پراسیسنگ کے ماہرین سے اس سلسلے میں بات کی تھی اور انہوں نے کافی مفید باتیں بھی بتائی تھیں۔ اگر اس فیلڈ میں کچھ کام کرنے والے سامنے آ جائیں تو کچھہی عرصے میں حوصلہ افزا نتائج سامنے آ سکتے ہیں۔
میں نے یہ تھیسس ڈیویلپ کیا تھا کہ اگر لگیچرز کی ایک ڈیٹابیس بن جائے تو تصویری متن کو پہلے افقی (horizontal) سمت میں پروسیسنگ کرکے اس کی سطور کو علیحدہ کیا جا سکتا ہے اور اس کے بعد ان سطور کو عمودی (vertical) سکیننگ کے ذریعے ترسیموں میں علیحدہ کیا جا سکتا ہے۔ اس طرح تصویری متن کے ترسیمہ جات تصویری شکل میں ہو جائیں گے جنہیں بصری شناخت کے مرحلے سے گزارا جا سکتا ہے۔ اس تھیسس کا سب سے بڑا مسئلہ یہ assumption ہے کہ تصویری متن کی سطور اور ہر سطر میں ترسیمہ جات کے مابین کچھ نہ کچھ سپیس ہے جس کی بدولت انہیں سادہ پروسیسنگ سے علیحدہ کرنا ممکن ہو سکتا ہے۔ لیکن جب میں نے تصویری اردو کے نمونے دیکھے تو معلوم ہوا کہ اکثر صورتوں میں یہ مفروضہ غلط ثابت ہوتا ہے۔ عام طور پر تصویری اردو کے نمونوں میں عبارت کافی تنگ نظر آتی ہے جس کی وجہ سے ک کی کشش پچھلے لفظ کے اوپر آ رہی ہوتی ہے اور اسی طرح سطور کے درمیان بھی سپیس نہیں ملتی۔ اس طرح اگرچہ تصویری متن سے ترسمیہ جات کا حاصل کرنا ناممکن نہیں ہو جاتا لیکن کم از کم سادہ پیٹرن ریکگنیشن سے ان کا حصول ممکن نہیں رہتا۔ اس کے لیے edge detection جیسے پروسیجر ہی کام دے سکتے ہیں جس پر کوئی امیج پراسیسنگ کے ماہر ہی کام کر سکتے ہیں۔
ایک طریقہ یہ اپنایا جا سکتا ہے کہ شروع میں ایسے ہی تصویری متن پر کام کیا جائے جو کہ مذکورہ بالا مفروضے پر پورا اترتا ہو، یعنی کہ اس کی سطور اور الفاظ کے درمیان کچھ نہ کچھ سپیس ضرور ہو۔ اس طرح کم از کم تحقیق آگے ضرور بڑھتی رہے گی۔ اگر اس میں کامیابی حاصل ہو جاتی ہے تو مزید پیچیدہ پرابلمز کو حل کرنے پر بھی غور کیا جا سکتا ہے۔
میں نے یہ تھیسس ڈیویلپ کیا تھا کہ اگر لگیچرز کی ایک ڈیٹابیس بن جائے تو تصویری متن کو پہلے افقی (horizontal) سمت میں پروسیسنگ کرکے اس کی سطور کو علیحدہ کیا جا سکتا ہے اور اس کے بعد ان سطور کو عمودی (vertical) سکیننگ کے ذریعے ترسیموں میں علیحدہ کیا جا سکتا ہے۔ اس طرح تصویری متن کے ترسیمہ جات تصویری شکل میں ہو جائیں گے جنہیں بصری شناخت کے مرحلے سے گزارا جا سکتا ہے۔ اس تھیسس کا سب سے بڑا مسئلہ یہ assumption ہے کہ تصویری متن کی سطور اور ہر سطر میں ترسیمہ جات کے مابین کچھ نہ کچھ سپیس ہے جس کی بدولت انہیں سادہ پروسیسنگ سے علیحدہ کرنا ممکن ہو سکتا ہے۔ لیکن جب میں نے تصویری اردو کے نمونے دیکھے تو معلوم ہوا کہ اکثر صورتوں میں یہ مفروضہ غلط ثابت ہوتا ہے۔ عام طور پر تصویری اردو کے نمونوں میں عبارت کافی تنگ نظر آتی ہے جس کی وجہ سے ک کی کشش پچھلے لفظ کے اوپر آ رہی ہوتی ہے اور اسی طرح سطور کے درمیان بھی سپیس نہیں ملتی۔ اس طرح اگرچہ تصویری متن سے ترسمیہ جات کا حاصل کرنا ناممکن نہیں ہو جاتا لیکن کم از کم سادہ پیٹرن ریکگنیشن سے ان کا حصول ممکن نہیں رہتا۔ اس کے لیے edge detection جیسے پروسیجر ہی کام دے سکتے ہیں جس پر کوئی امیج پراسیسنگ کے ماہر ہی کام کر سکتے ہیں۔
ایک طریقہ یہ اپنایا جا سکتا ہے کہ شروع میں ایسے ہی تصویری متن پر کام کیا جائے جو کہ مذکورہ بالا مفروضے پر پورا اترتا ہو، یعنی کہ اس کی سطور اور الفاظ کے درمیان کچھ نہ کچھ سپیس ضرور ہو۔ اس طرح کم از کم تحقیق آگے ضرور بڑھتی رہے گی۔ اگر اس میں کامیابی حاصل ہو جاتی ہے تو مزید پیچیدہ پرابلمز کو حل کرنے پر بھی غور کیا جا سکتا ہے۔