افضل حسین
محفلین
صبر کیجئے کچھ دنوں میں ضرور کام کرے گاموڈ خراب ہو گیا ایک لنک بھی کام نہیں کر رہا ۔۔
صبر کیجئے کچھ دنوں میں ضرور کام کرے گاموڈ خراب ہو گیا ایک لنک بھی کام نہیں کر رہا ۔۔
صبر کیجئے کچھ دنوں میں ضرور کام کرے گاموڈ خراب ہو گیا ایک لنک بھی کام نہیں کر رہا ۔۔
اگر یہ پروگرام ہو اور کام بھی کرتا ہو تو میں تو اس کے لئے مناسب قیمت تک دینے کو تیار ہوں")
اس کی قیمت کے بارے کچھ اندازہ؟ابھی ابھی سید منظر صاحب سے بات ہوئی انہوں نے بتایا کہ یہ پروجیکٹ دو مہینے کے اندر اندر مکمل ہوجائے گا ۔ انہوں نے مزید بتایا کہ نوری نستعلیق پہ اس کا نتیجہ 99٪ درست نکل رہا ہے
100ڈالر کے آس پاساس کی قیمت کے بارے کچھ اندازہ؟
اگر یہ پروگرام واقعی کام کرتا ہے تو سو ڈالر مناسب قیمت ہے100ڈالر کے آس پاس
اچھا فانٹ ہے۔ تاہم اس صفحے پر مجھے نستعلیق کا او سی آر دکھائی دیا ہے۔ پر لنک کام نہیں کر رہا
غالباً پروجیکٹ مکمل نہیں ہے یا مفت نہیں ہے
اگر یہ پروگرام ہو اور کام بھی کرتا ہو تو میں تو اس کے لئے مناسب قیمت تک دینے کو تیار ہوں
ابھی ابھی سید منظر صاحب سے بات ہوئی انہوں نے بتایا کہ یہ پروجیکٹ دو مہینے کے اندر اندر مکمل ہوجائے گا ۔ انہوں نے مزید بتایا کہ نوری نستعلیق پہ اس کا نتیجہ 99٪ درست نکل رہا ہے
پروگرام ڈاؤن لوڈ کر کے انسٹال کیا ہے لیکن ابھی کہیں دکھائی نہیں دے رہا کہ کہاں انسٹال ہوا ہے۔ شاید ری بوٹ سے فرق پڑے؟
پروگرام ڈاؤن لوڈ کر کے انسٹال کیا ہے لیکن ابھی کہیں دکھائی نہیں دے رہا کہ کہاں انسٹال ہوا ہے۔ شاید ری بوٹ سے فرق پڑے؟
C:\Program Files (x86)\Default Company Name\SetupProject\
میرے پاس پھر بھی نہیں چل رہا، تاہم یہ بات مزے کی ہے اس میں فانٹس کے دو فولڈر اور لیگچرز کی فائلز ہیں۔ عین ممکن ہے کہ اس میں مزید فانٹس کا اضافہ کرنا آسان ہو
The general framework of our approach as shown in Figure 5 consists of three main parts:
- Training which takes as input raw Arabic script data as text files. The training part outputs a dataset of ligatures, where each ligature is described by a feature vector.
- Recognition [...]
- User Interface [...]
The main goal of the training phase is to prepare the application to be used for text recognition for a certain Arabic script language. Training phase consists of two main steps:
1. Generation of a dataset of images for the possible ligatures of the Arabic script language to be used by the application.
2. Extracting features that describe each ligature in the dataset generated by the previous step.
Our system is initially trained to recognize both Urdu Nastaleeq and Arabic Naskh fonts. We have generated datasets for each language using Urdu and Arabic books available online as text files.
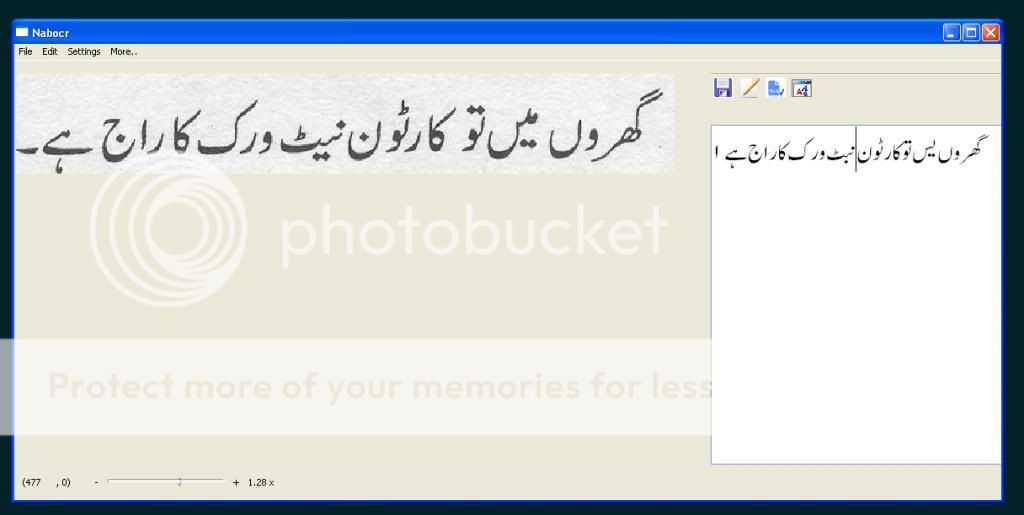
رفتار کی تو بس پوچھئے مت اس ایک سطر کو متن میں کنورٹ کرنے میں میرا مشین سوگیا۔ویسے یہ سوفٹ ویر ابھی ابتدائی مراحل میں ہے آگے جاکر یقینا اس میں پختگی آئے گی ۔ مجھے تو خوشی ہورہی ہے چلئے کم از کم اردو اوسی آر کی طرف پیشقدمی تو ہوئی ۔او سی آر انگریزی میں بھی سو فیصد نتیجہ مشکل سے ہی دیتا ہے۔ اس لئے پروف ریڈنگ میں چھوٹی موٹی غلطیاں نکل سکتی ہیں۔ اتنا کام ہو جانا بھی بہت اچھا ہے۔ اچھا ایک کام کیجئے کہ ایک سے زیادہ فائلز، جیسا کہ 50 یا 100 فائلز کو ایک وقت میں پروسیس کر کے دیکھیئے کہ کیا نتیجہ دیتا ہے۔ رفتار کیا ہے اور ان پٹ امیج کون سی فارمیٹ میں ہو۔ اگر تصویری متن کے ساتھ تصویر بھی ہو تو کیا نتیجہ دیتا ہے؟
آپ کے سسٹم کی ہارڈ وئیر اور سافٹ وئیر کنفگریشن کیا ہے، اگر بتانا چاہیں تو؟ ویسے یہ کافی حیران کن بات ہے کہ رفتار اتنی سست۔ تاہم اردو او سی آر کی طرف پیش قدمی واقعی بہت بڑی چھلانگ ہے کیونکہ او سی آر کے حوالے سے نستعلیق پیچیدہ ترین فانٹس میں سے ایک ہےرفتار کی تو بس پوچھئے مت اس ایک سطر کو متن میں کنورٹ کرنے میں میرا مشین سوگیا۔ویسے یہ سوفٹ ویر ابھی ابتدائی مراحل میں ہے آگے جاکر یقینا اس میں پختگی آئے گی ۔ مجھے تو خوشی ہورہی ہے چلئے کم از کم اردو اوسی آر کی طرف پیشقدمی تو ہوئی ۔
اگر ڈؤل کور ہے اور ہائپر تھریڈنگ نہیں تو پھر الگ بات ہے۔ میں کوشش کروں گا کسی وقت اسے اپنے آئی سیون پر انسٹال کر کے چیک کروں، سولہ جی بی ریم اور ہائپر تھریڈنگ کے ساتھ آٹھ پروسیسر اور ایس ایس ڈی ہارڈ ڈسکانٹیل آئی 3 پروسیسر
4جی بی ریم
چار سال سے کمپوٹر فارمیٹ نہیں ہوا اس لئے ویسے بھی کچھ سست ہے
[۔۔۔]اچھا ایک کام کیجئے کہ ایک سے زیادہ فائلز، جیسا کہ 50 یا 100 فائلز کو ایک وقت میں پروسیس کر کے دیکھیئے کہ کیا نتیجہ دیتا ہے۔ رفتار کیا ہے اور ان پٹ امیج کون سی فارمیٹ میں ہو۔ [۔۔۔]
میرے لیپ ٹاپ نے بھی اس سطر کو کنورٹ کرنے میں تقریباً دو منٹ صَرف کیے تھے۔رفتار کی تو بس پوچھئے مت اس ایک سطر کو متن میں کنورٹ کرنے میں میرا مشین سوگیا۔ [۔۔۔]
واہ! آپ کی آئی سیون مشین کی سپیسیفیکیشن پڑھ کر تو دل خوش ہو گیا! آپ اس مشین پر Nabocr کو ان مثالی صفحات کے ساتھ ضرور آزمائیے گا۔اگر ڈؤل کور ہے اور ہائپر تھریڈنگ نہیں تو پھر الگ بات ہے۔ میں کوشش کروں گا کسی وقت اسے اپنے آئی سیون پر انسٹال کر کے چیک کروں، سولہ جی بی ریم اور ہائپر تھریڈنگ کے ساتھ آٹھ پروسیسر اور ایس ایس ڈی ہارڈ ڈسک