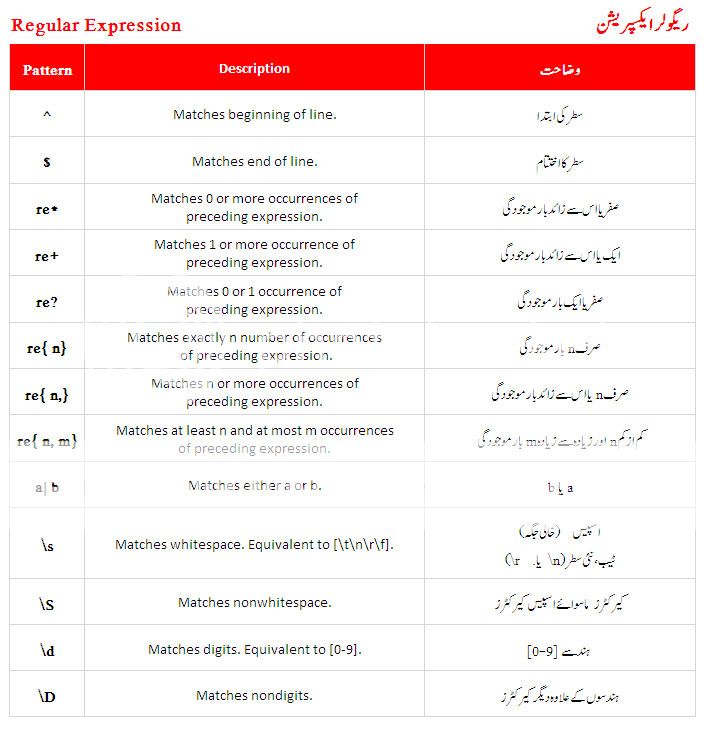
ریگولر ایکسپریشن اور ہندسے
ہندسوں کے لئے ریگولر ایکسپریشن میں
\d کا استعمال کیا جاتا ہے جب کہ ہندسوں کے علاوہ دیگر کیرکٹرز کی شناخت کے لئے
\D کا استعمال ہوتا ہے۔
درج ذیل مثال میں ہم ایک درست (valid) رول نمبر کو شناخت کریں گے۔ ہماری مثال میں ایک درست (valid) رول نمبر 4 ہندسوں پر مبنی ہوگا۔ یعنی ہمیں کوئی بھی رول نمبر صرف اس شرط میں قبول کرنا ہوگا جب وہ 4 ہندسوں پر مبنی ہو (نہ اس سے کم اور نہ اس سے زیادہ)۔
PHP:
>>> ab = '121'
>>> cd = '2554'
>>> ef = '14475'
>>> gh = '98'
>>>
>>> find_re(r'^(\d{4})$',ab)
Nothing found
>>> find_re(r'^(\d{4})$',cd)
Pattern found
>>> find_re(r'^(\d{4})$',ef)
Nothing found
>>> find_re(r'^(\d{4})$',gh)
Nothing found
ہماری مثال میں چار مختلف متغیرات (variables) کو مختلف رول نمبر (ہندسے) تفویض کئے گئے ہیں۔ ان رول نمبرز کو ہم نے اپنے ریگولر ایکسپریشن والے فنکشن کے تحت جانچا تو پتہ چلا کہ صرف متغر cd ہی ایسا رول نمبر ہے جو ہمارے درست رول نمبر کے معیار پر پورا اُترتا ہے۔ یعنی اس میں چار ہندسے دیے گئے ہیں۔ اس کے برعکس دیگر متغیرات میں یا تو رول نمبر میں دیئے گئے ہندسے چار سے کم ہیں یا چار سے زیادہ۔
اب ذرا بات ہوجائے عبارتی نمونے (Text Pattern) کی۔ ہمارا عبارتی نمونہ کچھ یوں ہے
'^(\d{4})$' ۔
کیرٹ سائن (^) سطر کی ابتدا کی نشاندہی کرتا ہے جبکہ ڈالر سائن ($) سطر کے اختتام کی۔ ہندسوں کی شناخت کے لئے
\d استعمال کیا گیا ہے۔ یعنی ہمارے مطلوبہ کیرکٹرز صرف ہندسے ہوں گے۔ اس کے بعد لہریے دار بریکٹ
{ } میں 4 کا ہندسہ موجود ہے۔ جس سے مراد یہ ہے کہ ہمارے مطلوبہ ٹیکسٹ میں صرف چار ہندسے ہوں گے (کم نہ زیادہ)۔
مزید کچھ مثالیں دیکھیے:
PHP:
>>> find_re(r'^(\d{3,})$',ab)
Pattern found
>>> find_re(r'^(\d{3,})$',cd)
Pattern found
>>> find_re(r'^(\d{3,})$',ef)
Pattern found
>>> find_re(r'^(\d{3,})$',gh)
Nothing found
>>>
یہاں ہم نے اپنے عبارتی نمونے میں 3 کے بعد ایک عدد کامہ (،) ڈال دیا ہے جس سے مراد یہ ہے کہ ہمارا مطلوبہ رول نمبر وہ ہے جس میں کم از کم 3 ہندسے ہوں، زیادہ سے زیادہ کی کوئی حد مقرر نہیں کی گئی۔ اب آپ دیکھ سکتے ہیں کہ متغیر gh کے سوا سب ہمارے (نئے) معیار پر پورے آگئے ہیں۔ کیونکہ gh میں صرف دو ہندسے موجود ہیں۔
کچھ اور مثالیں:
PHP:
>>> find_re(r'^(\d{0,3})$',ab)
Pattern found
>>> find_re(r'^(\d{0,3})$',cd)
Nothing found
>>> find_re(r'^(\d{0,3})$',ef)
Nothing found
>>> find_re(r'^(\d{0,3})$',gh)
Pattern found
>>>
اب ہم نے عبارتی نمونے میں ہندسوں کی کم از کم حد 0 اور زیادہ سے زیادہ 3 مقرر کی ہے۔ مثالیں اور اُن کے نتائج سے اس بات کا بخوبی اندازہ ہو جاتا ہے۔